The Role of Vector Database in Modern Data Management | Insights – Reshape Digital
May 27, 2024 by Filip Gagiu

It’s 2024 and vector databases are stepping out of the shadows and into the spotlight, marking a significant technological breakthrough. Alongside a surge of new technologies, vector databases are becoming essential tools that will transform and enhance our current technological world. But what exactly is a Vector Database and why would anyone need it?
What Are Vector Databases?
Imagine you have a large collection of photos and you want to find similar ones. Traditionally, databases might struggle with this because they’re designed to handle text and numbers, not complex media.
Here the vector databases come into play. A vector database is a type of database specifically designed to store, manage, and retrieve data represented as vectors. In simple terms, vectors are lists of numbers that can describe various types of data, like images, text, or audio. These vectors are often generated using techniques from machine learning or artificial intelligence, where complex data is transformed into numerical representations.
Why Vector Search Matters
Now back to the problem with the collection of images, a vector database can store each photo as a vector, which captures its unique features. When you search for a similar photo, the database can quickly find vectors that are close to the one you’re looking for. Vectors can represent more than just images, they’re used for text as well. For example, each word or sentence in a document can be turned into a vector that reflects its meaning. This makes it possible to search for documents that are semantically similar, even if they don’t contain the exact same words. It's like searching by meaning rather than by exact match. The power of vector databases comes from their ability to perform what’s called “similarity search.” This means they can efficiently find vectors that are similar to a given query vector. Think of it as finding things that are alike in a sea of data. This is particularly useful in fields like recommendation systems, where you want to suggest products similar to what a user has liked before.
Another advantage of vector databases is their ability to handle large volumes of data. As data grows, traditional databases can become slow and inefficient. Vector databases are optimized to handle these large datasets and perform searches quickly, making them ideal for modern applications that require real-time responses. In the world of AI and machine learning, vector databases are essential. They provide the backbone for applications that need to process and understand complex data. For instance, chatbots use vector databases to understand user queries and provide relevant responses, image recognition systems rely on vector databases to match new images with existing ones, and music companies use them as a means to find similar music to what you’ve listened to.
The usages of the vector database are endless, but how does one store a song or an image into a Database? In the realm of machine learning, data embedding refers to the process of converting complex data into a format that can be easily processed and analyzed. This is achieved by transforming data into vectors that encapsulate the essential characteristics of the original data, a practice known as vectorization. In natural language processing (NLP), text embedding is a technique to convert words, sentences, or documents into vectors. For example, Word2Vec, introduced by Google in 2013, learns vector representations of words by analyzing their contexts within a large collection. Each word is mapped to a point in a continuous vector space, where semantically similar words are located close to each other. This allows for effective similarity computations and semantic analysis.
Where Vector Databases Shine
Until now, we understood how a vector database breaks down data, stores it, and how it is used, but who exactly uses it?
Spotify developed Voyager, a high-performance nearest-neighbor search library designed to enhance its recommendation capabilities. As a music streaming service with millions of tracks, Spotify faces the challenge of organizing and retrieving relevant music efficiently. Voyager is built to perform nearest-neighbor searches in high-dimensional vector spaces. In the context of Spotify, each song, artist, or playlist can be represented as a vector that captures its unique attributes.
Google utilizes vector search technology to enhance the precision and relevance of search results. This technology enables Google to understand the nuances and meanings within the data, allowing for more refined content retrieval. For instance, vector search helps in aggregating content with similar semantic meanings, such as grouping terms like "films," "movies," and "cinema" together. But what about us?
How We're Using Them at Reshape Digital
At Reshape Digital, we faced the challenge of finding similar hotels based on various specific fields. The complexity and irregularity of the data, along with the need to match different features for similarity, made traditional database solutions inadequate. Our solution was to implement vector databases into our similarity search.
We employed Natural Language Processing (NLP) embeddings to vectorize the data of the hotel's features. This approach allowed us to convert complex, multi-faceted data into high-dimensional vectors that capture the semantic meaning of the features. By leveraging vector databases, we could efficiently compute the similarity between these vectors, enabling us to predict and retrieve the closest hotel matches to any given query.
This method significantly improved our ability to provide accurate recommendations and enhanced the overall user experience by ensuring that the hotels suggested were closely aligned with the users' preferences and search criteria.
More Insights
We write about what we build, how we think, and the decisions that shape real digital products.

Reshape Digital at London Tech Week
From healthcare to venture capital, we met with industry leaders across London Tech Week to explore AI, innovation, and the future of digital transformation. See what we learned, and where we’re heading next.

Reshape Digital at the London AI Summit
At the London AI Summit, we explored the enterprise future of generative AI, from data governance to fast-impact use cases in HR and customer service. Get our key takeaways from the front lines of AI adoption.

PoC for AI-Powered Drone Solution for Smarter Energy Grid Inspection | Insights – Reshape Digital
At the Energy Expo Cleantech Hackathon in Bucharest, Reshape Digital unveiled an AI-powered autonomous drone platform that redefines power grid inspection. The innovative solution earned a Special Mention for its impact on energy and sustainability.

Tokenizing Renewable Energy for a More Accessible Green Future | Insights – Reshape Digital
GreenVestX is a blockchain-based platform introduced at the Energy Expo Hackathon, designed to democratize renewable energy investments through tokenization. It empowers individuals to co-own and benefit from green energy.
Three Years of Reshape Digital | Insights – Reshape Digital
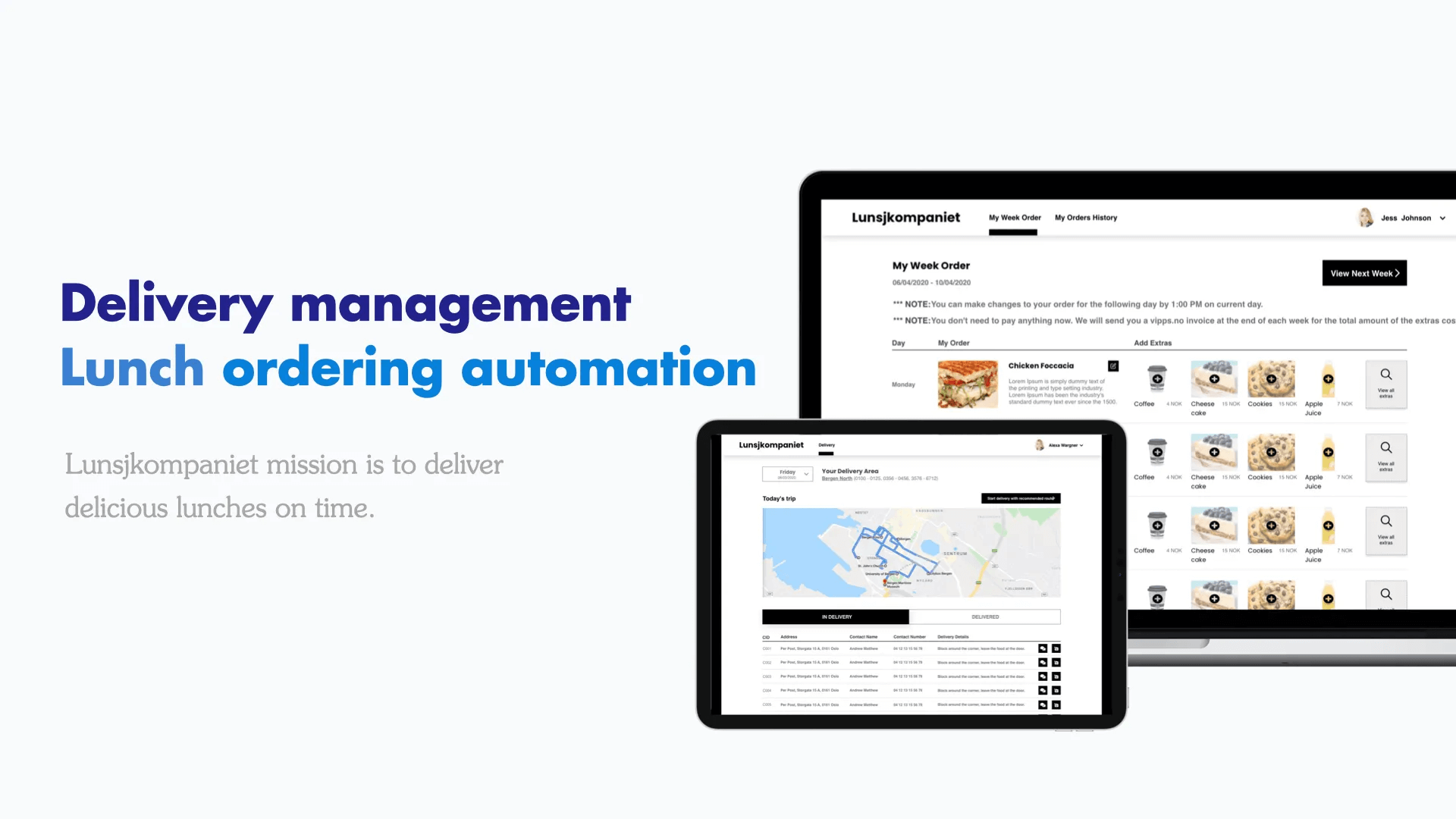
Paul Ionescu reflects on the three-year journey of Reshape Digital, from its humble beginnings with the first project, Lunsjkompaniet, to overcoming challenges like the pandemic and expanding into a thriving community of twenty colleagues.
How to develop a .NET Core 3.1 API secured with Identity Server 4 — Part 2 | Insights – Reshape Digital
Creating the API with Swagger integration and securing it using the Identity Server built in Part 1. Learn to configure authentication, authorization, and token-based access for your endpoints with real-world examples.

How to develop a .NET Core 3.1 API secured with Identity Server 4 — Part 1 | Insights – Reshape Digital
Dive into developing a .NET Core 3.1 API with Swagger, secured by Identity Server 4. This first part focuses on setting up the Identity Server project, including configuration and operational stores with SQL Server.

7 Essential things to think about when building an API | Insights – Reshape Digital
Security, architecture, testing, logging, documenting, versioning, caching, these seven components are critical for building a sustainable and scalable API. Here’s what you should consider from the very beginning.

Have you ever wondered how to make your Angular application extensible? | Insights – Reshape Digital
Learn how to build a plugin-based Angular architecture where external modules can be loaded dynamically at runtime, enabling feature decoupling, faster deployments, and even third-party extensibility.